
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- PAPER
- Alignments
- 카카오
- knn
- RMES
- n_neighbors
- 논문작성
- mes
- 파이썬을파이썬답게
- 코테
- n_sample
- 에러해결
- Pycaret
- Mae
- Python
- SMAPE
- MAPE
- 논문editor
- 논문
- TypeError
- KAKAO
- Tire
- 프로그래머스
- Overleaf
- 평가지표
- iNT
- 스택
- Scienceplots
- mMAPE
- python 갯수세기
Archives
- Today
- Total
EunGyeongKim
[deep learning] early stopping 본문
early stopping
- 너무 많은 epoch는 overfitting을 일으킴. 하지만 너무 적은 epoch는 underfitting을 일으키기 때문에 특정 시점에서 멈주어 정확도를 올리는것.
- early stopping은 Neural network가 과적합을 회피하도록 만드는 정칙화 기법중 하나. 훈련데이터와는 별도로 검증 데이터(validation data)를 준비하고, 매 epoch마다 검증데이터에 대한 오류(validataion loss)를 측정하여 모델의 훈련종료를 제어함.
- 과적합이 발생하기 전까지는 training loss와 validation loss가 감소하지만, 과적합이 일어나면 training loss는 감소하는 반면에 validation loss 는 증가함.
- 그러므로 early stopping은 validation loss 가 증가하는 시점에서 훈련을 멈추도록 조종
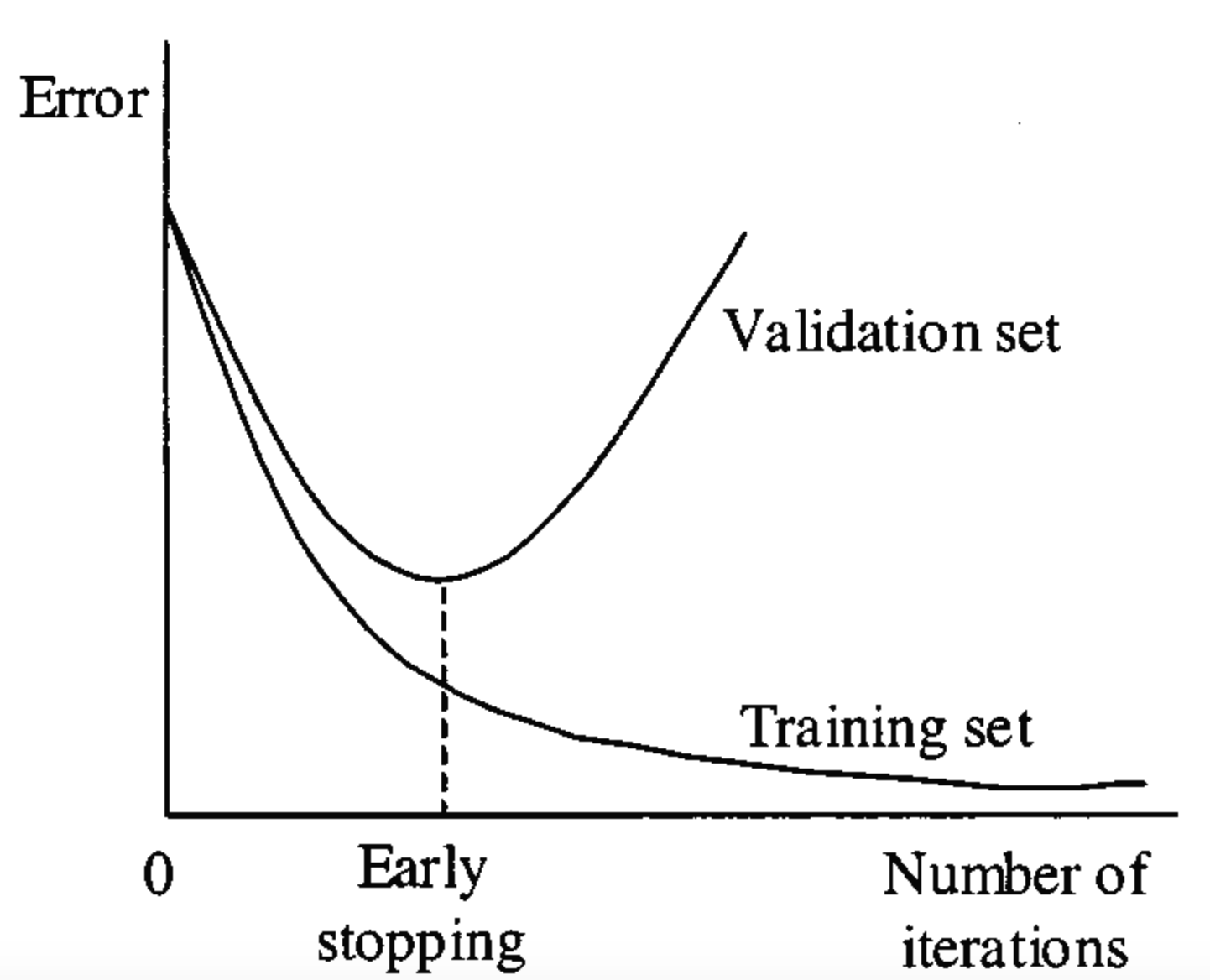
어디에서 사용가능한지?
- Keras의 EarlyStopping 함수
from keras.callbacks import EarlyStopping
earlyStop=EarlyStopping(monitor="val_loss",verbose=2,mode='min',patience=3)
test_model = model.fit(x_train, y_train, epochs = 10,
...., callbacks=[earlyStop])- 클래스 구성요소
- performance measure : 어떤 성능을 monitoring 할 것인지
- trigger : 언제 training 을 멈출것인지
python 코드
라이브러리 선언
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from tensorflow.keras.layers import LSTM, Dense
from tensorflow.keras.models import Sequential
from keras.callbacks import EarlyStopping
import tensorflow as tf
GPU 설정
gpus = tf.config.experimental.list_physical_devices('GPU')
tf.device("/gpu:0")
데이터 불러오기
spring = open("kor_spring.csv", "r")
data_spring = pd.read_csv(spring, header=0)
seq_spring = data_spring[['temp','sunshine', 'insolation', 'div_solar']].to_numpy()
lstm에서 사용할 데이터를 나눠주는 함수
def seq2dataset(seq, window, horizon):
X = []; Y = []
#총 데이터 길이 - (7+1) + 1 만큼 반복
for i in range(len(seq)-(window + horizon)+1):
x = seq[i:(i+window)]
y = (seq[i+window+horizon-1])
X.append(x)
Y.append(y)
return np.array(X), np.array(Y)
변수 선언.
window = 24, h = 1
24(w)개단위로 나누고, 1시점(h) 후의 값을 예측
w = 24
h = 1
데이터 나눠서 x_spring, Y_spring에 넣기
# 윈도우 크기, 수평선계수 설정
X_spring,Y_spring = seq2dataset(seq_spring, w, h)
훈련집합 나누기
전제 데이터 - 24 = 훈련 데이터
맨 끝 24개 데이터 = 검증데이터
# _spring
# 훈련집합 나누기
split = int(len(X_spring)-24)
x_train_spring = X_spring[0:split]
y_train_spring = Y_spring[0:split]
x_test_spring = X_spring[split:]
y_test_spring = Y_spring[split:]
모델 학습 및 early stopping 설정
monitor = "val_loss" ( val_loss값을 토대로 early stopping 판단)
patience = 3 (만약 3번이상 val_loss가 증가하거나 감소하면 멈춰주기)
mode = 'min' (val_loss측정을 min으로 할건지, max로 할건지 판단하는 모드)
batch_size = 한번에 돌려줄 노드 갯수
verbose = 학습시킬때 출력될 진행상태 표현(취향껏 고르기)
callback = early stopping같은거 집어넣으면 됨.
# _spring
# LSTM 모델 설계와 학습
earlyStop=EarlyStopping(monitor="val_loss",verbose=2,mode='min',patience=3)
model_spring = Sequential()
model_spring.add(LSTM(units=10, input_shape=x_train_spring[0].shape))
model_spring.add(Dense(4))
model_spring.compile(loss='mae', optimizer= 'adam', metrics=['mae'])
hist_spring = model_spring.fit(x_train_spring, y_train_spring, epochs=5000,
batch_size=100, validation_data=(x_test_spring, y_test_spring), verbose=2, callbacks=[earlyStop])
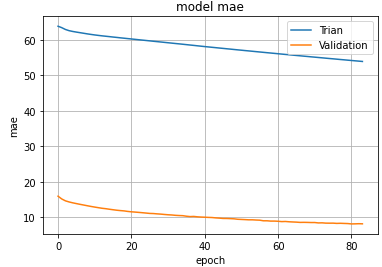
결과값.
82, 83, 84 epoch가 3번 연속으로 증가하여early stopping 됨.
너무 빨리 멈춘듯함.
이런경우 patience를 늘려주면 될듯
Epoch 81/5000
109/109 - 0s - loss: 54.2049 - mae: 54.2049 - val_loss: 8.1837 - val_mae: 8.1837 - 437ms/epoch - 4ms/step
Epoch 82/5000
109/109 - 0s - loss: 54.1115 - mae: 54.1115 - val_loss: 8.2029 - val_mae: 8.2029 - 433ms/epoch - 4ms/step
Epoch 83/5000
109/109 - 0s - loss: 54.0236 - mae: 54.0236 - val_loss: 8.2428 - val_mae: 8.2428 - 436ms/epoch - 4ms/step
Epoch 84/5000
109/109 - 0s - loss: 53.9305 - mae: 53.9305 - val_loss: 8.2121 - val_mae: 8.2121 - 439ms/epoch - 4ms/step
Epoch 00084: early stopping
학습곡선 그려주기
# _spring
# 학습곡선
plt.plot(hist_spring.history['mae'])
plt.plot(hist_spring.history['val_mae'])
plt.title('model mae')
plt.xlabel('epoch')
plt.ylabel('mae')
plt.legend(['Trian', 'Validation'], loc = 'best')
plt.grid()
plt.show()
자세한 Github 코드
reference
- https://3months.tistory.com/424
- https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=cjh226&logNo=221468928164
'ML & DL' 카테고리의 다른 글
| [NN] MNIST 분류 Neural Network (0) | 2022.07.22 |
|---|---|
| [pycaret] Knn 오류 (Expected n_neighbors <= n_samples,) (0) | 2022.04.22 |
| [통계] 기초통계 (0) | 2022.02.05 |
| [머신러닝] EDA(Exploratory Data Analysis) 탐색적 데이터 분석 (0) | 2022.02.04 |
| [ML] 예측방법과 종류 (0) | 2022.02.03 |
'ML & DL' Related Articles
more


Comments