
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- TypeError
- mMAPE
- n_sample
- 프로그래머스
- Alignments
- 파이썬을파이썬답게
- 카카오
- Scienceplots
- 코테
- Pycaret
- MAPE
- iNT
- SMAPE
- knn
- 논문작성
- mes
- Mae
- 논문
- 평가지표
- PAPER
- Overleaf
- Python
- 논문editor
- n_neighbors
- Tire
- RMES
- 스택
- python 갯수세기
- 에러해결
- KAKAO
- Today
- Total
EunGyeongKim
[데이터 전처리] 정규화 (Normalization) 본문
정규화란 데이터의 중요도를 같은 정도로 반영하게 해 주는것을 말하며, 데이터가 가진 feature의 스케일을 일정 범위의 값으로 조정해 주는 것을 말한다.
이를 특성 스케일링(feature scaling), 또는 데이터 스케일링(data scaling)이라고 한다.
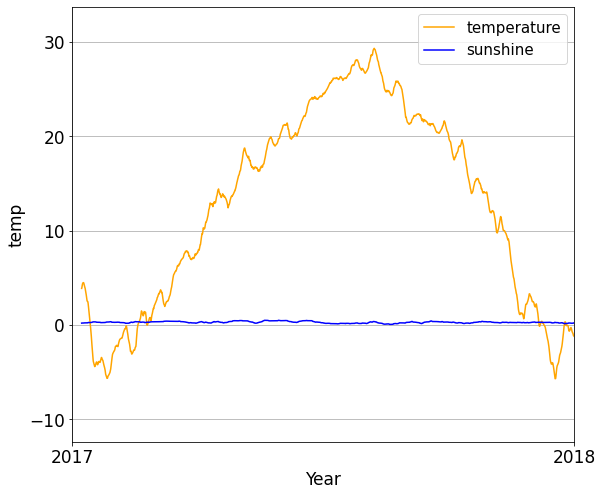
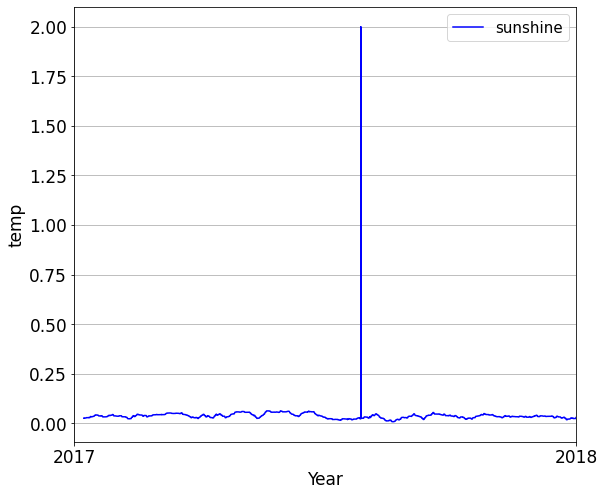
위 사진은 2017년에서 2018년 사이의 기온과 일사량 그래프이다.

보시다시피 기온은 약 -5도 ~ 30도 사이의 값을 가지지만, 일사량 값은 0~1사이의 값을 가진다.
이 값을 그대로 비교할 수 있겠지만, 그렇게 한다면 scale 값이 큰 기온 값에 의해 결과에 많은 영향을 미치게 됩니다.
그러므로 두값을 동일한 범위로 변환 시킴으로써 기온값과 일사량 값의 중요도를 동일하게 맞춰주어야 합니다.
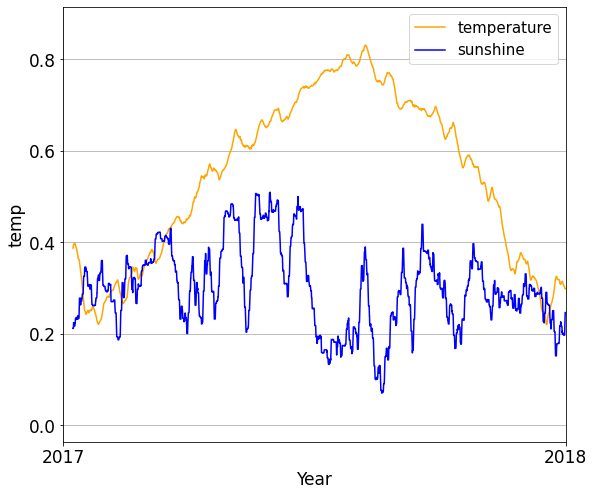
데이터를 정규화를 하는데는 여러가지 방법이 있습니다.
대표적으로는 Min-Max Normalization, Z-score, Standardized moment, Coefficient of variation 등이 있습니다.
아직 공부하는 학생이니 틀린 내용이 있다면 부드럽게 지적해 주시길 바랍니다.
Min-Max Normalization
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
data = scaler.fit_transform(data)
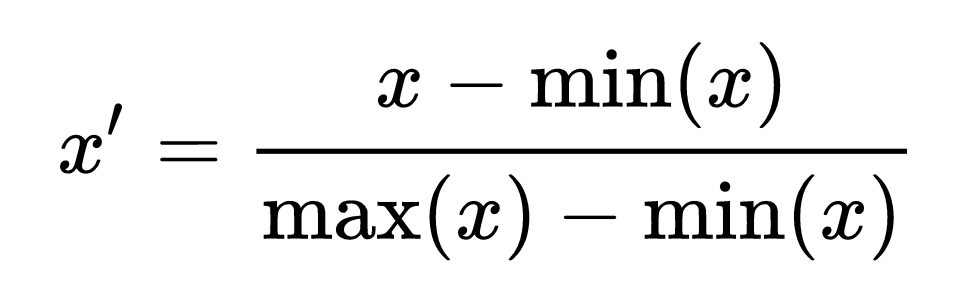
데이터의 Max값과 Min값을 이용하여 값을 0~1 사이의 값으로 변환해 줍니다.
가장 일반적인 방법이지만 이상치(outlier)에 큰 영향을 받습니다.
일사량값은 주로 0~1사이의 값을 가지지만 예시로 5000번째 일사량 값을 2로 설정하였습니다. (이상치 설정)
이렇게 되면 min-max normalize를 하더라도 그래프가
위와같은 상태가 되기 때문에 scale을 조정해주는 정규화가 의미없어집니다.
Z-score Normalization
import pandas as pd
from scipy.stats import zscore
data = zscore(data)
#여기서부터는 그래프 출력
plt.figure(figsize = (9,8))
plt.plot(data['sunshine'], color = "r", label = "sunshine")
plt.plot(data['temp'], color = "b", label = "temp")
plt.legend(fontsize = 15)z-score는 데이터의 평균과 표준편차의 값을 이용하여 평균대비 몇 표준편차만큼 데이터가 떨어져 있는지를 점수화합니다.

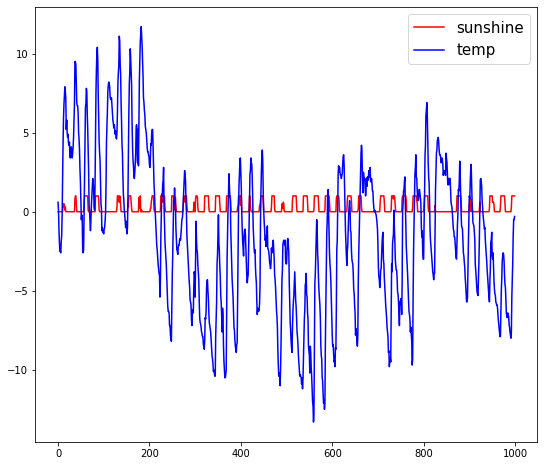
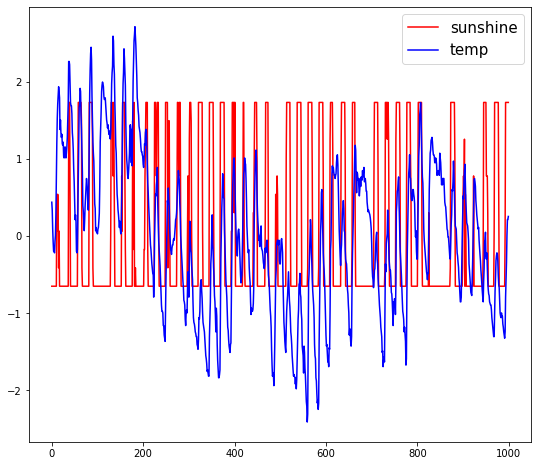
여기서 500번째 sunshine 값을 2로 설정해 보지요(이상치 설정)

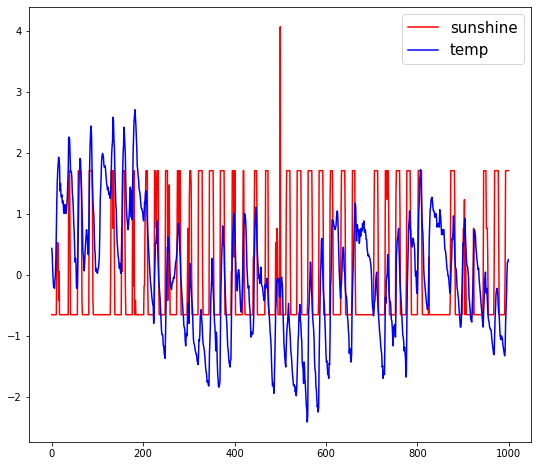
z-score를 해도 sunshine의 값이 약간 튀어나오긴 했지만, min-max만큼은 아닌것을 확인할 수 있습니다.
'ML & DL > 딥러닝' 카테고리의 다른 글
| 머신러닝에 필요한 수학과 numpy코드 (0) | 2023.02.20 |
|---|---|
| 그래프 그리기 (0) | 2023.02.20 |
| 딥러닝 단어 정리 (0) | 2022.07.23 |
| [NN] MNIST 분류 Neural Network (0) | 2022.07.22 |
| [deep learning] early stopping (0) | 2022.02.06 |

